

TinyML is the latest from the world of deep learning and artificial intelligence. It brings the capability to run machine learning models in a ubiquitous microcontroller – the smallest electronic chip present almost everywhere
Microcontrollers are the brain for many devices that we use almost every day. From a TV remote controller to the elevator to the smart speaker, they are everywhere. Multiple sensors that can emit telemetry data are connected to a microcontroller.
Actuators, such as switches and motors, are also connected to the same microcontroller. It carries embedded code that can acquire the data from sensors and control the actuators.
The rise of TinyML marks a significant shift in how end-users consume AI. Vendors from the hardware and software industries are collaborating to bring AI models to the microcontrollers.
The ability to run sophisticated deep learning models embedded within an electronic device opens up many avenues. TinyML doesn’t need an edge, cloud, or Internet connectivity. It runs locally on the same microcontroller, which has the logic to manage the connected sensors and actuators.
The Evolution of TinyML
To appreciate the power of TinyML, we need to understand the evolution of AI in the cloud and at the edge.
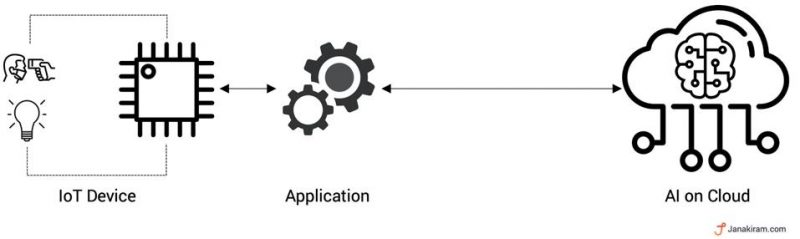
Phase 1 – AI in the Cloud
During the early days of AI, the machine learning models were trained and hosted in the cloud. The massive compute power needed to run AI made cloud the ideal choice.
Developers and data scientists leverage high-end CPUs and GPUs to train the models and then hosting them for inference. Every application that consumed AI talks to the cloud. This application would talk to the microcontroller to manage the sensors and actuators.
Phase 2 – AI at the Edge
While the cloud continues to be the logical home for AI, it does introduce latency while consuming the deep learning models. Imagine every time you speak to a smart speaker, the request going to the cloud for processing. The delay involved in the round trip kills the experience.
Other scenarios, such as industrial automation, smart healthcare, connected vehicles, demand AI models to run locally.
Edge computing, a conduit between the cloud and local IoT devices, became an ideal choice for hosting the AI models locally. AI running at the edge doesn’t suffer from the latency involved in running the same in the cloud.
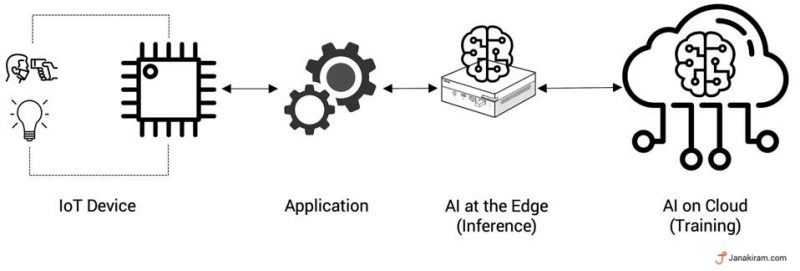
But given the limited resources of the edge, training and retraining models still require cloud. Trained models can be hosted at the edge for inference – the process of consuming machine learning models – but not for training. So, it became common to train the models in the cloud and deploy them at the edge.
This approach provides the best of both worlds – a powerful compute environment for training (cloud) and a low-latency hosting environment for inference (edge).
While using AI at the edge, the microcontrollers acquire telemetry from the connected sensors, which is sent to a locally deployed model for inference via an application. The model then returns the prediction or classification of input data, which is used to decide the next steps.
Phase 3 – AI in the Microcontroller
While running AI at the edge is a perfect solution for many use cases, there are scenarios where deploying an edge computing layer is not practical. For example, connecting consumer devices like smart speakers and remote controllers to an edge is overkill.
It increases the total cost of ownership of devices and support costs for vendors. But these consumer devices are hotbeds for infusing AI capabilities.
In industrial scenarios, predictive maintenance is becoming an essential part of the equipment. The expensive machinery and equipment need to embed machine learning models that detect anomalies in realtime to deliver predictive maintenance. By proactively detecting failures, customers can save millions of dollars in maintenance costs.
Embedding AI directly in the microcontroller is becoming key for both consumer and industrial IoT scenarios. This approach doesn’t depend on an external application, edge computing layer or the cloud. The AI model runs alongside the embedded code flashed to the microcontroller. It becomes an integral part of the overall logic delivering unmatched speed.
Traditionally, machine learning models have always been deployed in environments with rich resources. Since TinyML models can be embedded in microcontrollers, they are not resource-intensive. This approach is the most efficient and cost-effective way of infusing AI into IoT devices.
The Growing Ecosystem of TinyML
Though TinyML is in its infancy, there is a vibrant ecosystem in the making. Electronic chip and IoT kit makers such as Adafruit, Mediatek, Arduino and STM are supporting TinyML in their devices. Microsoft’s Azure Sphere, the secure microcontroller, can also run TinyML models.
TensorFlow Lite, a variation of the popular open source deep learning framework, can be ported to supported devices. Another open source machine learning compiler and runtime, Apache TVM, can also be used to convert models into TinyML.
Emerging AutoML and TinyML platforms such as Always AI, Cartesiam, EdgeImpulse, OctoML and Queexo are building tools and development environments to simplify the process of training and optimizing models for microcontrollers.
TinyML makes AI ubiquitous and accessible to consumers. It will bring intelligence to millions of devices that we use on a daily basis.
Source: Forbes
How USDA Digitized Their Processes with E‑Signatures in Record Time





