

Com diversas aplicações na solução de problemas reais, as tecnologias voltadas à visão computacional têm se proliferado em diversas áreas. Um dos usos populares destas tecnologias está na medicina, nas tarefas de diagnóstico por meio da extração de informações das imagens de radiografias, ultrassonografias, ressonâncias etc.
Outros cases conhecidos sobre visão computacional são os carros autônomos, que são capazes de reconhecer as sinalizações das vias por meio do processamento das imagens das placas em tempo real, obtendo assertividade até maior que a humana. Tais soluções são usadas inclusive na exploração espacial em veículos autônomos como o usado na Mars Exploration Rover, da NASA.
As aplicações não param por aí: a indústria utiliza esses métodos para análise de qualidade de produtos; a agronomia aplica a visão computacional na irrigação das plantações; os sistemas de reconhecimento facial identificam pessoas univocamente etc.
Uma questão intrigante é: como o computador consegue “ver” se ele não é detentor das complexas fisiologias dos seres vivos?
De fato a visão computacional não é trivial e só foi possível graças ao trabalho de diversos pesquisadores que estudaram intensivamente a aplicação de Redes Neurais Convolucionais (CNN) em tarefas reais.
Uma das primeiras demonstrações ocorreu nos anos 90, quando o cientista de computação francês Yann LeCun construiu uma CNN para reconhecimento de caracteres manuscritos da famosa base de dados MNIST.
Outro famoso desafio de aplicação das CNN é no reconhecimento dos objetos da eclética base de dados ImageNet que possui mais de 14 milhões de imagens. Em 2011, a taxa de erro obtida nessas competições era em torno de 25%, já em 2012, um modelo de CNN chamado AlexNet conseguiu uma taxa menor, de 16%. Em 2017, a acuracia obtida pela maioria dos times da competição era maior que 95%.
A tecnologia por trás do processamento e classificação de imagens não é simples, entretanto é composta por modelos muito interessantes que vale a pena compreender.
Este artigo traz uma visão introdutória sobre as CNN. Para um entendimento mais aprofundado, é necessário uma leitura mais técnica e completa.
Visão Humana x Visão Computacional
De forma resumida, na visão humana a imagem é captada pela retina e enviada para os neurônios responsáveis por compreendê-la e classificá-la.
Uma bicicleta, por exemplo, é classificada como bicicleta pelo cérebro por possuir características específicas de bicicletas como: rodas, quadro, manopla, selim, pedais, entre outros.
Caso a bicicleta esteja sem uma roda, por exemplo, mesmo assim o sistema humano consegue realizar a correta classificação, visto que pode abstrair a falta de alguma parte ou alguma diferença estética ou estrutural.
No treinamento de uma CNN, acontece algo semelhante, as Redes neurais convolucionais recebem imagens (que para o computador são matrizes de pixeis referentes às cores da imagem) e aplicam filtros, que possibilitam a extração de características. Após essa extração, utilizam a camada de rede neural para classificar a imagem.
Como não se trata de um processo trivial, abaixo estão minimamente detalhadas algumas das etapas e requisitos desse processamento.
Seleção das imagens para treinamento da CNN
Para que o treinamento da rede seja eficiente, é imprescindível que o dataset de imagens que serão usadas para treinamento seja extenso e possua fotos do objeto em diferentes posições, cores, iluminação, perspectiva.
A base ImageNet, por exemplo, possui mais de 1800 fotos de Gatos. A MNIST possui também uma grande quantidade de imagens do mesmo caractere manuscrito.
Caso não se possua um dataset extenso o bastante para trazer maior generalização para o algoritmo, pode-se usar técnicas para rotacionar e entortar as imagens e com isso, gerar novas imagens do objeto.
As imagens precisam ser tratadas a fim de possuírem a mesma dimensão. Essas imagens são compreendidas pelo computador como matrizes. No exemplo abaixo, da base MNIST, é possível observar matriz da imagem referente ao 4 manuscrito. Observe que se trata de uma matriz de 28 x 28 pixels, onde os pixels responsáveis por representar a letra estão em tons de cinza.
Extração de características
Na visão humana, há o reconhecimento de características que classificam um objeto, já as CNN realizam esse procedimento por meio de aplicação de filtros.
Os filtros são matrizes menores que percorrem os pixels da imagem de entrada e geram novas imagens (Feature map). Na aplicação dos filtros, é realizada uma operação matemática entre a matriz da Imagem de Entrada (I) e Filtro (K), gerando os Feature Maps (I*K). Esse processo é denominado Convolução.
Na prática, o filtro (Kernel) percorre toda a imagem de entrada e gera um mapa resultante deste processamento.
O processo de convolução pode ser executado seguidas vezes, até se obter Feature Maps adequados.
Nesse processo, podem ser aplicadas técnicas de pooling, padding, ativação e outras funções que permitem à rede extrair boas features da imagem. Um dos grandes desafios do Cientista de Dados é configurar essas camadas de forma a obter a maior eficiência no processo de classificação.
Flattening
Uma vez que os mapas foram extraídos, aplica-se a técnica de flattening para transformação da matriz resultante das convoluções em um vetor com 1 coluna e N linhas, que dará entrada na camada densa da rede, responsável por classificar a imagem.
Camada Densa
Esta camada é uma rede neural que será treinada para classificar os vetores resultantes do processo de Flattening.
Ela possuirá uma quantidade razoável de neurônios que receberão como entrada o vetor. Esta rede poderá possuir diferentes camadas e utilizar algumas técnicas específicas como DropOut, para aprimorar os resultados.
As redes neurais utilizam a técnica de Backpropagation para atualização dos seus pesos com o objetivo de alcançar a menor taxa de erro na camada de saída, que classificará o objeto.
Dada a importância desta técnica, pode-se dizer que o backpropagation é o algoritmo mais importante das redes neurais, pois sem ele seria impossível realizar o treinamento das redes com a eficiência obtida atualmente.
Esse algoritmo possui duas fases: Forward Pass quando há a propagação dos valores da entrada através da rede e Backward Pass onde é calculado o gradiente da função de perda da camada final e aplicada recursivamente a regra da cadeia (derivadas parciais compostas) para atualização dos pesos. Com isso, a rede neural consegue aprender os melhores pesos e se adaptar para classificação do objeto.
De forma didática e resumida, sem a pretensão de demonstrar toda a complexidade do processo, pode-se observar que a Rede Neural Convolucional possui a seguinte estrutura:
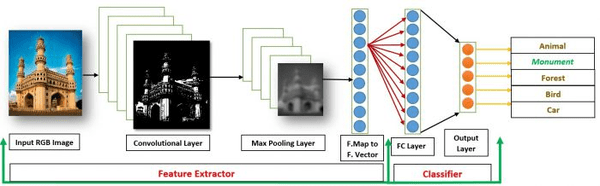
Após o treinamento dessa rede, é gerado um modelo de classificação que poderá ser utilizado nos processos de classificação de uma aplicação específica, podendo ser um carro autônomo lendo placas da cidade, uma câmera identificando pessoas pela face, um equipamento de irrigação diferenciando as plantas…
Essa é uma explicação bem sintética e despretensiosa de uma das mais populares tecnologias aplicadas na visão computacional. É importante mencionar o imenso arcabouço matemático, estatístico e tecnológico que permitiu a criação e aplicação desta incrível tecnologia.
Infraestrutura para visão computacional
As técnicas de backpropagation, ativação, cálculos entre matrizes, e outros, são problemas estudados há décadas pelos matemáticos que só puderam ser aplicados com o advento de computadores capazes de realizar esse complexo e pesado processamento.
Apesar de servidores com processadores tradicionais do tipo CPU (Unidades de Processamento Central) serem utilizados nessas tarefas, o reconhecimento de imagens por meio de CNN ganhou fôlego com a utilização dos chips GPU’s (Unidades de Processamento Gráfico).
As GPU’s são processadores para computação gráfica altamente otimizados para processamento de operações repetitivas, como o treinamento destes algoritmos, pois são capazes de efetuar cálculos matemáticos de forma veloz e paralelizada.
Implementação de CNN
Outro fator que tornou o uso das CNN mais acessível foi o lançamento de diversas bibliotecas que abstraem boa parte da complexidade matemática dessas redes, tornando o treinamento e geração de modelos CNN muito mais simples, tais como Keras, Torch, TensorFlow.
Apesar desse estado da arte, é importante mencionar que o desenvolvimento desses modelos não é trivial, pois há diversas decisões estratégicas durante a montagem dos algoritmos e na análise dos resultados que dependem de conhecimentos matemáticos, estatísticos, computacionais e de negócio.
O Cientista de Dados precisa estar apto a realizar essas análises, o que torna esse profissional muito valioso para as organizações.
Fonte: Serpro
Regulamentação da Inteligência Artificial no Brasil deve prever o essencial: a supervisão humana
Assistentes virtuais: tendência ou porta de entrada para cibercriminosos?
As melhores atualizações sobre inteligência artificial você encontra aqui!
[button link=”https://cryptoid.com.br/blog/” icon=”fa-check-circle-o” side=”left” target=”” color=”1abfff” textcolor=”ffffff”]Explore outros artigos![/button] digital






